Reading text from images
In this post, I’ll try to give some basic understanding about the difference between a raw text and a text represented by an image, then give an overview of a common approach to the problem of text recognition.
Text image and raw text
For a computer, there is a huge difference between a text and an image that contains text. When we input characters of a text using the keyboard, for example, the computer can easily know if we have inputted an “a” or a “k”, because it has specific representations for each symbol, representations for the signals sent by the keyboard. In another hand, images of a text can have almost infinite different representations in the computer, like those of the figure below.

A digital image is usually represented as a matrix of integer values in the interval $[0, 255]$, which means that the image is just a composition of unicolored small parts called pixels. For gray scale images, zero represents black, 255 represents white and the other values are shades of gray 1. Color images are commonly represented by three matrices: $R$ (red pixels values), $G$ (green pixels) and $B$ (blue pixels), like a composition of three gray scale images. The next figure shows three different image representations of the letter “e”; although the pixels values are different in each matrix, humans can easily identify the character.
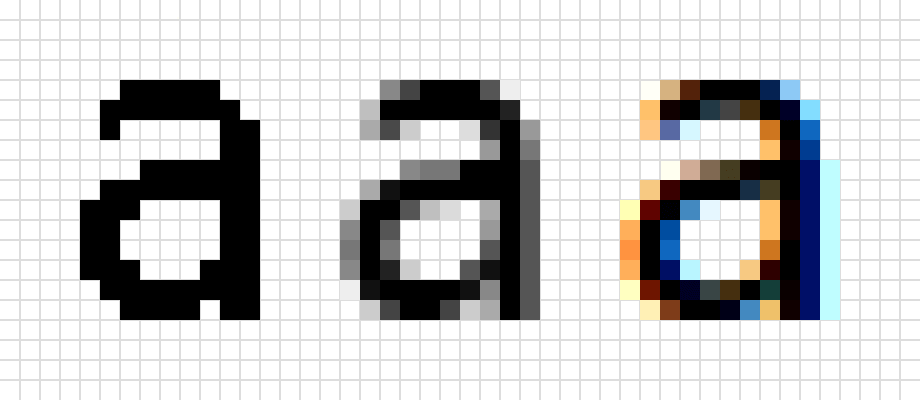
Although the computer sees images just like agglomerates of data, we can make it learn to extract some meanings from them. We did learn to interpret images too. The human eyes works very similarly to a camera, sending electrical signals to the brain, which is responsible to interpret and to give them some meaning. But usually we are not aware of this process, our brains have learnt it very well when we were just babies.
So, how could we teach a computer to extract some meaning from an image? In the case of texts, that is where Optical Character Recognition (OCR) comes in.
How OCR works
Roughly speaking, the OCR process usually involves two different steps: text detection/localization and character recognition.
The first step is responsible for reducing the complexity of the image and for finding the simplest image unit for recognition, an isolated character, feeding its results to the next step. The character isolation is important because usually classifiers can’t classify whole words or sentences (think about the number of different categories such classifier would need to handle, all possible combinations of the characters).
The figure below shows one very common technique to segment the characters of a text. The bar chart indicates the number of pixels at the column $x$ whose values are below some gray shade value (that must be between the characters’ gray value and the background’s gray value). We can note that the small gaps between the characters are easily identified by the zero $y$ value in the chart, giving us good $x$ coordinates to split the image.
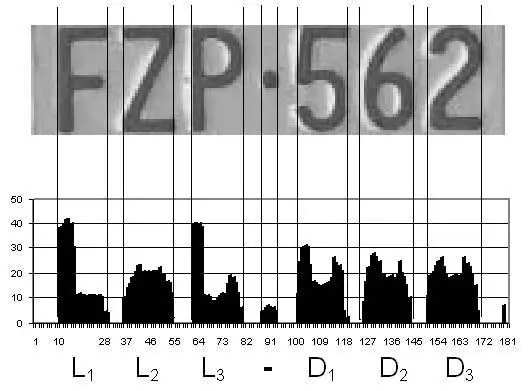
Once we have all image patches containing single characters, we are ready to apply a character classifier. The “traditional” problem of the character recognition is to find patterns for each character class. Given the simplest image unit for an OCR system, the image of a single character (look again at the second figure), this system needs to assign a character class accordingly to the pixels values. This task would be easy if every image of an “e” was always the same, i.e., if their pixels values were always the same values. But any slight difference of illumination, rotation angle or typeface could be enough to make the pixels values look very different from other images of the same character class.
One possible approach to the problem is to map the pixels values into points in a feature space. With each character image represented by a point in the feature space, the OCR system could try to find patterns in those points’ positions and their respective character class. Then, each new character image would be mapped into the same feature space and the most similar pattern would be matched, giving the most likely character class of the image.
Perhaps the most obvious feature space is that composed of the own pixels values, where the number of pixels gives the dimension of this space. For example, for images of size 4x4, the feature space would be $\mathbb{N}_{<256}^{16}$, a sixteen dimensional space where each dimension could assume an integer value in the interval $[0, 255]$. A whole image would be represented as a point in that space. The next figure shows two examples of feature spaces, a 2D and a 3D; each point would represent the features (height, width, density, etc., for example) of an image and the colors indicate two different categories (like two different letters).
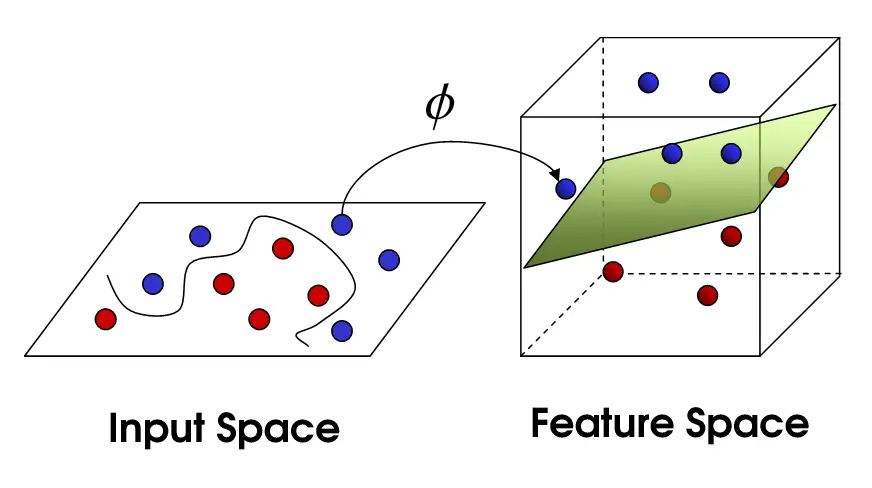
Considering this idea, we could think about a simple way to compare the similarity between images: the Euclidean distance. Labeled images $x_l^i$ (character class $l$, labeled sample $i$) can be used to guess an unlabeled image $x$ by measuring the Euclidean distance $d_l^i(x_l^i, x)$ and taking the label $l$ of the smallest $d_l^i$. In another words, we are taking the class of the nearest neighbor 2 of $x$ in the feature space. Considering again the figure above, an unlabeled image would be another point, but without color; its color would be assigned by its closest colored point.
OCR trends
Probably the hottest research fields in machine learning today, the application of Deep Neural Networks. to image processing has moved the image understanding to another level. As its own name says, DNNs are similar to normal neural networks, but they are deeper because of their bigger number of hidden layers.
In the OCR field, DNNs has been used to recognize better text in natural images or photographs, where the visual appearance of text has a wider variability than scanned documents.
One very interesting application was showed in this paper from a Google’s research team. There a DNN (similar to the bottom-left model of next figure) is used to recognize a whole word (or a sequence of numbers) at once, i.e., the network recognizes the characters without any explicit text segmentation, without isolating single characters. Recaptcha images, that are usually very hard to be segmented into single characters, were easily recognized by such DNN. Another very interesting application can found here, where we can find DNN architectures, like those of the figure below, used for text recognition in natural scene images. However, although these networks are very powerful, their training is usually harder than the training of other popular ML techniques.

I hope to explore some of theirs details in another post.
Conclusion
In this post I tried to give a brief description of the main concepts of OCR systems. We have seen that, at least for computers, there is a big difference between raw text and text images. Text images are just matrices of integers values for computers, but we can “teach” them to extract some meanings from them. Finally, a very quick overview of how the rise of Deep Neural Networks have shown impressive results and promises a new range of applications for OCR.
References
- http://en.wikipedia.org/wiki/Optical_character_recognition
- http://www.explainthatstuff.com/how-ocr-works.html
- http://www.andrewt.net/blog/posts/how-to-crack-captchas/
- http://en.wikipedia.org/wiki/Infant_vision
- http://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
- http://devblogs.nvidia.com/parallelforall/accelerate-machine-learning-cudnn-deep-neural-network-library/
- Mohammed Cheriet, Nawwaf Kharma, Cheng-lin Liu, and Ching Suen. 2007. Character Recognition Systems: A Guide for Students and Practitioners. Wiley-Interscience.
- Goodfellow, I., Bulatov, Y., & Ibarz, J. (2013). Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks. Retrieved from http://arxiv.org/abs/1312.6082
- Jaderberg, M., Simonyan, K., Vedaldi, A., & Zisserman, A. (2014). Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition, 1–10. Retrieved from http://arxiv.org/abs/1406.2227v4
-
Binary images are gray scale images with just totally black and/or totally white pixels, which are usually represented with 0s and 1s instead of 0s and 255s. ↩
-
This is the basic idea of a very common machine learning algorithm called k-Nearest Neibors. ↩